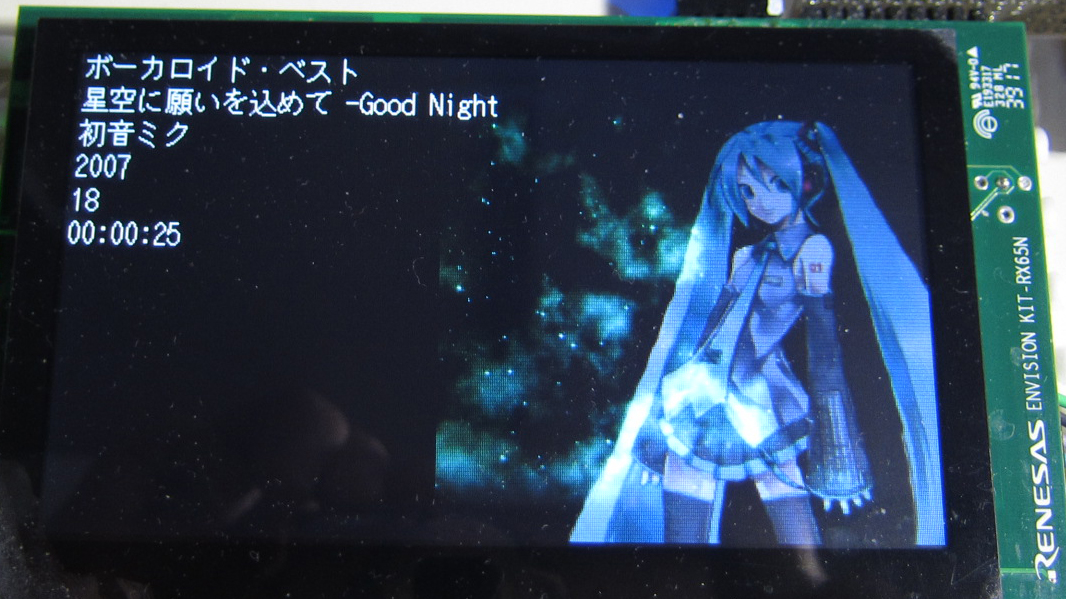
picojpeg デコーダーのポーティングが出来たので、ID3 タグ内のジャケット画像などを格納するタグ「APIC、PIC」内データ(JPEG)をデコードして画像表示は出来たのだが、画面サイズにフィットさせるのは後回しになっていた。
まず、仕組みを考える・・
画面デザインから、画面の右端に272×272ピクセル(液晶の縦ピクセル)で表示させるのが良さそうだ。
ただ、タグ内の画像サイズは様々なので、適切にスケーリングする必要がある。
スケーリングの方法も重要だ、RX65Nの内蔵メモリはあまり大きく無いので、画像のような大きなデータを扱う場合、出来れば、一時メモリを使用しない(利用できない)方が良い。
それらを踏まえて、画像のデコーダーテンプレートは、直接画像の操作を扱うAPIを叩かないで、中間に「スケーリング」を行うオブジェクト(クラス)を入れる事にした、こうしておけば、レンダリングを行う対象がどんな場合にも対応可能となる。
typedef graphics::render<uint16_t, LCD_X, LCD_Y, AFONT, KFONT> RENDER;
RENDER render_(reinterpret_cast<uint16_t*>(0x00000000), kfont_);
typedef img::scaling<RENDER> PLOT;
PLOT plot_(render_);
typedef img::picojpeg_in<PLOT> JPEG_IN;
JPEG_IN jpeg_(plot_);C++ では、「ファンクタ」と呼ばれる方法(通常「()」オペレーターを使う)で、クラスに対しての操作を一般化できる。
//-----------------------------------------------------------------//
/*!
@brief 描画ファンクタ
@param[in] x X 座標
@param[in] y Y 座標
@param[in] r R カラー
@param[in] g G カラー
@param[in] b B カラー
*/
//-----------------------------------------------------------------//
void operator() (int16_t x, int16_t y, uint8_t r, uint8_t g, uint8_t b) noexcept
{
・・・
}まず、plot_ クラスに対して、スケールを設定する。
※スケールは、「整数比」で設定する。
※画像全体を収める為、縦か横で長い方を基準にする。
auto n = std::max(ifo.width, ifo.height);
plot_.set_scale(272, n);
jpeg_ クラス内から、plot_ クラスに対して、以下のように普通に描画すれば、設定された拡大、縮小比で描画される。
※ワークメモリを使わないのと引き換えに、描画する領域は、あらかじめ「0」クリアしておく必要がある。
plot_(x, y, r, g, b);
また、描画時にオフセットを与えられるようにしてある。
plot_.set_offset(vtx::spos(480 - 272, 0));最初、縮小をさせる場合に、エイリアシングを考慮しない簡易的な実装を行ってみたのだが、当然のように描画品質はあまり良くない。
※ジャギジャギしてる・・
そこで、ピクセルの加重割合を考えずに平均化してみる事にした。
・フレームバッファはRGB565となっている。
・フレームバッファを読み出して、「0x0000」なら、初期に書き込むピクセルとして、そのまま書き込む。
・もし、新規に書き込むピクセルが「0x0000」なら、「0x0001」に直して書き込む。
・フレームバッファを読み出して、「0x0000」以外なら、既に書き込まれている値なので、新規に書き込む値との平均(1/2)を求めて書き込む。
この実装は、厳密な意味では正確ではないものの、「ジャギー」感が減り、かなりマシに見える。
とりあえず、これで良しとした、ピクセルサイズによる厳密な加重平均や、フィルタ的要素は、次の課題とする。
※現状では、「拡大」する場合は、簡易的なものになっていて「ジャギー」が目立つ。